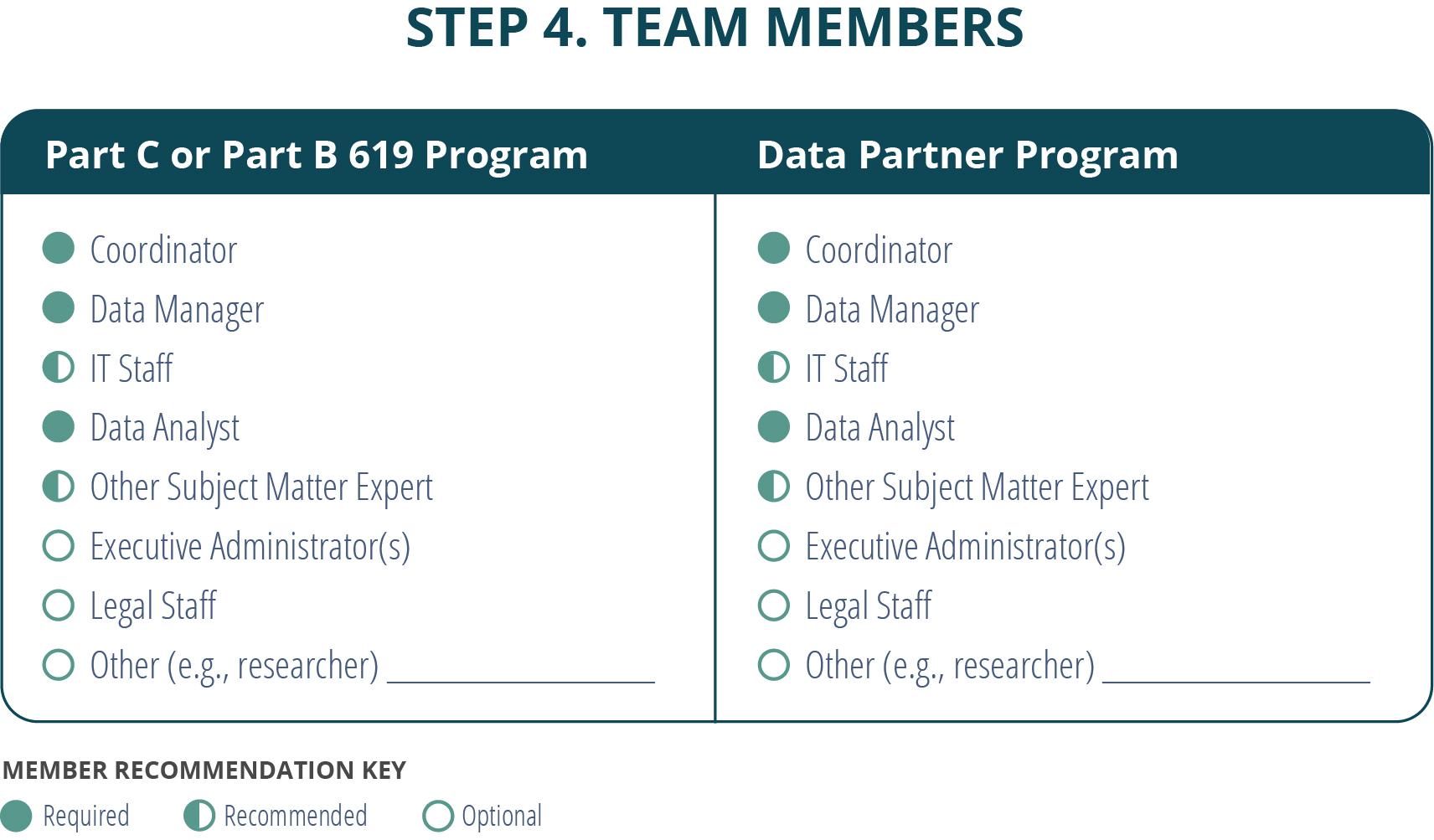
In Step 4, data linking partners begin the more technical activities. Whether Part C or Part B 619 program staff are linking data within their own program or with another agency or program, successful data linking requires a number of technical activities. Because some activities are iterative, decisions made during one may require data linking partners to return to one or more previous activities. For example, the partners may return to identifying data elements to improve the number of potential matching records. Additionally, some activities may not be required. For example, if data linking partners share a common unique ID, they should move directly to standardizing the data elements in Activity 4g. The table below displays the roles of team members potentially involved in Step 4 activities.
TIP: Although data can be linked manually, data linking partners usually use software to compare records and link the data. Step 4 describes the major activities required to link data without regard to specific software. No matter the software used, Part C and Part B 619 program staff are encouraged to access and use the suite of tools (e.g., Align, Connect) that the Common Education Data Standards (CEDS) initiative created to facilitate data linking.
Activity 4a: Select record-matching approach
What about linking non-child records?
Most Part C and Part B 619 data are focused on the provision of services to children. Therefore, examples in this toolkit focus on linking child-level records. However, in some cases, Part C or Part B 619 program staff may need to link workforce or program-level data to answer key questions about policy and program improvement. Regardless of whether linking is focused on child-level, workforce, or program-level data, or any combination of these, partners need to follow the same basic activities.
A shared unique ID across data sets greatly facilitates data linking activities. If data linking partners share a unique ID, they can skip Activities 4a–4e associated with the matching process. However, many data sets do not share a unique ID. In these instances, it is important to establish a record-matching approach. There are two primary approaches for matching records: deterministic and probabilistic.
Deterministic matching is a process that requires exact matching of all selected elements for two records to be considered a match. All selected elements (e.g., birthdates, names, sex) must be exact matches. If any element differs between two records, it is considered a nonmatch. However, methods can be used to account for “equivalencies” (e.g., Bill and William, Rd and road). Deterministic matching often uses a limited number of elements in the matching algorithm—generally only elements unlikely to change.
There are advantages and disadvantages to deterministic matching. An advantage is that it is easier (and faster) because records either match or do not match—there are no “unknown” records to investigate. A disadvantage is that deterministic matching will miss matches that have small discrepancies. Take, for example, a deterministic algorithm that matches records on date of birth, sex, last name, and first name. If one data set has a record that matches a record in the other data set on everything but last name (e.g., Smith vs. Smyth), that record would be classified as a nonmatch. Although the two records likely represent the same child, deterministic matching would not match the records and there would be no investigation.
Probabilistic matching is a process of coding matches and potential matches based on degrees of similarity between the matching elements. Probabilistic matching weighs each element and assigns a resulting score. Based on the match score, record pairs are sorted into three groups: confidently matched, confidently unmatched, and unknown. Record pairs with scores above a certain cut point are coded as confidently matched. Record pairs with scores below a certain cut point are coded as confidently unmatched. If scores fall between those cut points, record pairs are coded as unknown and require further investigation.
Consider two records in which a child’s date of birth, sex, first name, last name, and mother’s maiden name match exactly across two data sets. But ZIP code is also included in the matching algorithm, and the code differs in the two records. This match will likely generate a high enough score to be coded as confidently matched, requiring no investigation. However, in the same example, if both ZIP code and first name do not match, the score may fall within the unknown range. In this case, the records will need to be investigated to determine whether they are or are not a matched pair.
Probabilistic matching also has advantages and disadvantages. An advantage is that, when similar records do not match perfectly (i.e., they fall in the unknown range), they are investigated. As a result, the number of matched records is maximized. However, probabilistic matching requires more time and effort to set up the element match value, generate an acceptable matching algorithm, and investigate unknown but possible matches.
Probabilistic matching is frequently used when maximizing the number of matches is a priority. It tends to use more elements than deterministic matching in part to support the investigation of potential matches. When data linking partners choose probabilistic matching, they will identify the number of elements to include in the matching process, the scores to assign each matching element, the ranges for each group (confidently matched, confidently unmatched, and unknown), and the business rules for finalizing unknown matches.
Activity 4b: Identify data elements for use case
Next, data linking partners must select data elements from both data sets that will enable matching (if needed) and support all the analyses. The partners must determine which elements one or both partners will contribute. Some elements will be strictly used for analysis, others for matching, and some for both.
TIP: If an element found in both data sets is not used for matching or analysis, it is not necessary to include it in the linked data set.
TIP: Data dictionaries are often the best source of information to understand details on elements within the data sets.
Activity 4c: Select data elements for the use case
Partners must identify and include all elements needed to answer the data linking use case in the linked data set. Each use case dictates the elements needed. Some common Part C or Part B 619 elements include but are not limited to the following elements:2
Disability or reason eligible (HI, DD, established condition, etc.)
IDC-9/IDC-10 code
Service type (PT, OT, VI)
Setting or education environment
Service level (hours, frequency, intensity)
Dates to support service duration (service beginning and end dates)
Other program involvement data reported by Part C or Part B 619 families (foster care, CAPTA, EHDI)
The partners will likely need additional demographic elements to address the use case, especially when disaggregating and comparing data across subpopulations. Some common Part C or Part B 619 child and family demographic elements include but are not limited to the following elements:
Child date of birth (to calculate age)
Sex
Race/ethnicity
Primary language
Home ZIP code (to establish geographical areas)
Medicaid or free or reduced-price lunch eligibility (as a proxy for socioeconomic status)
Activity 4d: Select data elements for matching
Demographic elements used for disaggregation as part of the use case analysis are also frequently selected to match records. Depending on the matching approach, data linking partners may select primary and secondary elements for matching. Deterministic matching relies solely on primary matching elements whereas probabilistic matching often includes primary and secondary elements.
Primary matching elements are least likely to change and serve as strong differentiators in the matching process. Examples of frequently used primary matching elements are:
Child’s date of birth
Mother’s maiden name
Child’s last name
Child’s first name3
Sex4
TIP: Even if all the primary matching elements listed are not initially included in the matching algorithm, they may be useful later if the algorithm is modified.
Risks When Using Race and Ethnicity as a Secondary Matching Element
Although race and ethnicity are common elements likely found in both data sets and are important for analysis, they present unique challenges that could negatively impact the matching algorithm:
There may be differences in data collection methods across agencies or programs.
Race and ethnicity are usually self-reported, and respondents may report their race or ethnicity differently for different programs.
Respondents may choose not to provide these data (resulting in missing data or unreliable data based on perception by data entry staff).
Secondary matching elements are often less stable but quite helpful when investigating possible or unknown matches in probabilistic matching. These are examples of frequently used secondary matching elements:
Probabilistic matching requires data linking partners to assign scores to elements. Assignment of scores is based on each element’s stability and matching importance. For example, the partners would assign much higher scores to primary matching elements such as child’s date of birth and mother’s maiden name than they would to secondary matching elements such as phone numbers or email addresses.
TIP: Err on the side of selecting more secondary matching elements (within reason) even if they are not initially used in the algorithm. More secondary matching elements are helpful when investigating unknown records. Additional secondary matching elements may also be used in any modification to the matching algorithm.
TIP: Consider assigning element scores that sum to 100.
Activity 4e: Create matching algorithm
Determining how many elements to match against, which elements to match, and what scores to assign those elements is part art and part science. It is an iterative process of adjusting the scores, and possibly the elements, during the matching process. DaSy recommends that data linking partners consider at least three primary matching elements and at least four secondary matching elements if they are using probabilistic matching. Then, the partners assign scores to each element. If the partners are using deterministic matching, they assign scores to only primary matching elements.
TIP: When using probabilistic matching, consider having at least two-thirds to three quarters of the total possible score generated by primary matching elements. (This can be adjusted later if needed.)
TIP: Data partners will likely need to tweak the algorithm multiple times to capture the most matches.
The number of elements used for matching depends on a variety of factors. When selecting elements, data linking partners should consider the following.
What should you do if the information for the same data elements differs across data sets?
For some use cases, the differences between data sets on a specific element might be important to the analysis. In those instances, the final linked data for a single record would include potentially differing information from both data sets for a matched record. This would complicate the analysis. DaSy recommends that data linking partners carefully consider whether differing data for the same element is important to the use case.
There is a point of diminishing returns after a certain number of elements are included in the matching algorithm.
Researchers may need more elements if they require 100% confidence that all matched records are indeed the same entity (e.g., for submission to a refereed journal).
Although program work requires high-confidence levels, it does not require perfection (i.e., 100% confidence).
A higher number of matching elements increases the chance that one or more elements will not match. Yet a higher number of matching elements increases the level of confidence that the corresponding record has been found in both data sets.
Fewer matching elements may result in false positives. That is, the returned match is two different individuals instead of one individual.
More elements provide more information when investigating unknown matches.
The level of acceptable matching confidence, and the number of elements included in the matching algorithm, can vary depending on the purpose of the data linking effort.
TIP: Don’t let the “quest for the perfect matching algorithm” prevent or significantly delay linking data.
Activity 4f: Establish business rules
Business rules are criteria used to make decisions about data. In data linking, business rules are needed for at least two reasons. The first is when an important element for a confidently matched record pair differs. The second is to investigate unknown matches.
Business rules for addressing differences in confidently matched record pairs
When the two data sets have the same data for the same element for a matched record pair, all is well. But when the data for an important element for a confidently matched record pair differ across the data sets, data linking partners need to establish and activate business rules. The partners must determine which source should be captured for that one differing element. This is called the “source of authority/truth.”
To determine the source of authority, data linking partners need to know the processes used to initially collect and record information. Knowing this can help them choose one data set over the other as the authoritative source for a specific element. In Step 1, the partners should have considered and discussed data quality strengths and potential weaknesses of both data sets. While developing the business rules, the partners might importantly learn, for example, that one program commonly verifies child demographic data from birth certificates. In this case, the partners could set a logical business rule: When a child’s birth date or sex differs between two otherwise matched records, consider the program most likely to have verified the data as the source of authority. The information from the authoritative data set would be captured in the linked data and used to address the use case.
Another common business rule is latest entry. If all things are equal (e.g., neither program has verified data on a specific element), data linking partners might establish the rule that they will use the most recently entered data. This is especially applicable for elements subject to change. For example, socioeconomic status (SES) is often important for analysis. If both data sets have a proxy for SES, such as eligibility for Medicaid or free or reduced-price lunch, and neither program has verified SES, a logical business rule might be to use the most recently entered data from either source.
Ideally, data linking partners develop business rules before standardizing data for matching, but they frequently develop additional business rules later to address issues discovered during earlier rounds of data matching work. Generally, partners create business rules only for data elements common to both data sets and/or for those necessary for use case analysis.
TIP: If data linking partners plan to replicate the data linking in the future, they should continue to add and refine business rules.
Business rules for investigating unknown matches
When using probabilistic matching, data linking partners will encounter unknown record pairs that require deeper investigation. Establishing business rules for investigating unknown matches provides a consistent process for the investigation. Ideally, one or more informed individuals who know the data can assist the partners in investigating unknown matches. With ongoing or repeated data linking, the partners are likely to add more business rules as new issues arise.
The following are recommended logical business rules to begin an investigation of unknown matches.
Start with the matches that have the highest scores. Often these records narrowly missed the confidently matched cut point. Many of the highest-scoring unknowns are likely matched record pairs. Conversely, many of the lower-scoring unknowns may not be matches.
Accept the obvious. Is there a minor spelling, or misspelling within a text field? Consider differences in names (e.g., Smythe vs. Smith) or variations of names (e.g., Robert vs. Bob) as matched elements. Sometimes, street type differs (e.g., road, lane, avenue) but can be considered equivalent when all other elements within the record pair match.
Ignore the source data on an element that is an obvious data entry error (e.g., a date of birth making a child ineligible for the program).
Look elsewhere in the dataset for clues. For example, if birth years differ and in one data set referral date precedes birth year, it is likely that the birth year in that data set is incorrect.
Check a third data source, if available. Online services can support an investigation into directory information.
Ask those closest to the source (e.g., a service provider) to double-check any source documents they may have.
TIP: Remember to document business rules as they are created and refer to them regularly. Staff change and memories fade.
TIP: If variance is consistently high on one compared element, it may be that this element should not be used to match records due to data quality issues. Alternatively, the score of this element might be reduced in any updated matching algorithm.
Activity 4g: Standardize data elements
Data elements for matching or analysis should be in a consistent format across data sets. For example, dates (e.g., date of birth, service start date, service end date) can be formatted as a single data field or multiple fields. Even in a single field, dates can be formatted differently (e.g., MM/DD/YYYY, MM/DD/YY, September 29, 2021). All date-related elements in both data sets that will be used for matching or analysis should have the same format. If the format differs, data linking partners will need to transform (modify) one data set to align with the other data set. The partners should document standardization rules to accommodate future linking of the data sets.
TIP: If an element found in both data sets is not used for matching or analysis, there is no need to standardize it because it will not be included in the linked data set.
The table below provides suggestions on how to standardize commonly used elements.
Data Element
Standard
Notes
Dates
MM/DD/YYYY
Convert dates to standard format. Leave invalid dates blank.
Sex
M/F (alpha or numeric)
Convert to single-digit alpha or numeric.
Race/ethnicity
Alpha or numeric
Convert to single or dual element format with alpha or numeric options. (Ideally, race and ethnicity are two separate elements.)
Names
Alpha only
Have separate fields for first and last names.
Remove special characters, suffixes (e.g., Jr), and blanks (Mary Jo to MaryJo).
Consider adding name equivalency rules (William = Bill, Billy, Willy). For ongoing linking, rules can be added over time as new examples are found.
To differentiate siblings from multiple births, be sure to include first name—at minimum, include initial of first name.
Address (multiple fields)
Street address (or PO box)
City
State
ZIP code
Have separate fields for each part of an address (street number, street name, city, ZIP code).
State is usually changed to two-character abbreviation.
Change zip+4 into two fields (when one data set has only 5-digit zip code).
For most Part C and Part B 619 data linking work, state would not be included as a matching
element.
Phone numbers
(XXX) XXX-XXXX
Convert phone numbers to standard format.
Other elements as needed
Activity 4h: Match records
After establishing the initial matching algorithm, setting business rules, and standardizing data elements, data linking partners can begin matching records. This involves comparing the matching elements in each record in one data set with those in each record in the other data set, based on the predetermined matching algorithm.
Probabilistic matching results in many unknown or potential matches that require investigation to determine whether they are confidently matched or confidently unmatched. Although partners create the probabilistic matching algorithm (data elements and scores) before linking the data, they often need to refine the algorithm during the matching process. The time they spend developing and refining a good matching algorithm and assigning appropriate scores will lead to fewer unknown matches and less time investigating unknown matches.
Matching records in data sets is both an art and a science. The science is tweaking the probabilistic matching algorithm, trying different matching elements, and adjusting their scores. The art is knowing when an acceptable algorithm is found. Running slightly different algorithms and comparing the results (percentages of matches, nonmatches, and unknowns) is common.
TIP: There are programs designed to compare and match large data sets. However, common software programs frequently found on desktop computers (e.g., Microsoft Excel or Access) can also do the work. Data linking partners can use a desktop application or a program designed for matching.
TIP: Adding name equivalency rules will accommodate comparing different iterations of the same name (Robert vs. Bob vs. Bobby). Also, sound-alike software is available to find records that have differently spelled names but are likely the same.
TIP: After running each matching algorithm, add a field to indicate matched, unmatched, and unknown record pairs. Record the results of each matching algorithm. When running different matching algorithms on an entire data set, use the results to compare the effectiveness of those different algorithms.
DaSy suggests that data linking partners first investigate unknown matches with the highest scores and then work down the list until the unknown records reach a certain score. (Because the goal is to minimize the number of unknowns through a solid algorithm, the partners should document the “stop” point score if they will repeat the linking exercise in the future.) Depending on the number of records being processed and the algorithm used, some residual “tough to say” unknown matches may remain. Ideally, the partners will meet, consider, and determine as best as they can whether those remaining cases are matched or unmatched.
After completing these determinations, but before linking all data elements, partners should take time to double-check the matching process and the results. Quality assurance activities may include spot-checking an appropriate number of matched records against the original data source to confirm that nothing was inadvertently transformed, misaligned, or otherwise disordered.
Once matching is complete, data linking partners can prepare the statistical results of the final matching (and possibly the results of each matching iteration performed on the entire data set). The partners should run descriptive statistics summarizing the matching: the numbers and percentages of records that initially matched with confidence, did not match with confidence, and were unknowns. Also, depending on the importance and scrutiny of the data linking effort, the partners may need to report in some detail on the resolution of the unknown records: the percentages determined to be matched and unmatched after investigation. Both partners, along with subject matter experts, should review these matching results to ascertain whether they are reasonable and within the expectations of those most knowledgeable about the programs. Although highly unlikely, if the percentage of matched records differs considerably from those expectations, the partners could stop the data linking activities at this point.
The investigation into unknown record pairs will likely uncover probable data entry errors in the source data. Differences in name spellings, dates of birth, sex, directory information, and so on can be expected in many unknown record pairs eventually determined to be matches. Data linking partners should plan to share a list of records with differences between data sets with the source data stewards so that they may have an opportunity to clean their source data.
Activity 4i: Create joined data set and check data quality
Once record matching is final, partners can link the data from the two matched records. Linking combines all the selected elements from the two matched records into a single new record in a new data set.
After the data are linked, it is important to check the integrity of the technical linking (i.e., check that the records were accurately combined). The partners should spot-check an adequate number of records to make sure the linked elements in the new data set are identical to the elements in both original data sources. This ensures that nothing was missed or incorrectly performed in the important linking activity.
Activity 4j: Certify joined dataset
Program or agency staff and leadership should carefully review the results of the matching, linking, and analysis before signing off on the data linking work. In some cases, program or agency leadership will be comfortable with certifying the work before the analysis is conducted (Step 5) and the results made available. In other cases, especially when interested stakeholders are awaiting the results of the linked data, certification may need to wait until after the use case has been addressed (i.e., after the data are analyzed and possibly a report drafted for internal review). Eventually, all parties must agree that the data linking was conducted accurately and is complete.
2 The elements shown are from the list of elements in the DaSy Data System Framework, subcomponent System Design and Development, Quality Indicator 3. 3 First initial is sometimes used to reduce issues with misspellings or nicknames. 4 Sex is an important element for analysis and is usually brought in and matched across datasets. However, it is frequently not scored in the algorithm.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.